Disponibilité
Par disponibilité il faut entendre la disposition, la présence de tous les éléments nécessaires à l'accomplissement d'une tâche. Généralement il s'agit du fichier, de l'information, du système d'exploitation, du programme de traitement, du réseau (dans la plupart des cas) et, pour ne pas oublier le facteur humain, de(s) utilisateur(s) "formé(s)". Nous décelons à prime abord donc trois éléments : l'humain, l'information et la technique. |
 Disponibilité 7/7 Disponibilité 7/7© TICSIPD fotolia 2010 |
| La disponibilité de l'humain, de l'information et de la technique dépend de facteurs très divers ayant toutes fois un point commun : l'humain. Il se trouve dans les trois éléments : - l'humain parmi les humains, un ensemble complexe de relations plus ou moins formelles, - l'information pour laquelle il (humain) se préoccupe (sécurité de l'information, protection des données), - la technique utilisé par l'humain pour traiter l'information, la gestion, exploitation, la maintenance de la technique, la sécurité, la disponibilité de la technique. Nous parlerons ici de la disponibilité technique, l'humain n'étant pas directement le sujet de notre thème et nous traiterons à de nombreuses autres occasions de l'information sur ce site. |
|
De manière générale, et d'un point de vue technique, on estime qu'un système informatique (donc plusieurs machines) doit avoir les caractéristiques suivantes :
⇒ availability disponibilité (panne et niveau de service non dégradé),
⇒ scalability monté en charge, capacité d'adaptation à la charge de travail
⇒ reliability fiabilité, système dans un état cohérent, fournit des infos correctes
⇒ manageability le système est gérable comme s'il ne s'agissait que d'une machine
⇒ single-system image le système est vu de l'extérieur comme un seul système.
Ces termes empruntés à la langue anglaise n'ont pas forcément de traduction directe en français. De plus, les auteurs ne les définissent pas tous de la même manière.
Availability ou disponibility
Par disponibilité s'entend la caractéristique du système d'être toujours disponible à répondre aux besoins, théoriquement à tous les besoins, dépendant des moyens financiers mis derrière. C'est la capacité d'un système à répondre à une demande indépendamment du nombre d'utilisateurs et des demandes en cours de traitement.
La difficulté en terme de CNS (Contrat de Niveau de Service / SLA Service Level Agreement) est de définir la limite entre un système disponible et non disponible. A quel moment et sur la base de quels critères un système avec de mauvais temps de réponse sera considéré comme non disponible. La propriété de <<scalabilité>> d'extension, de variabilité, permet d'augmenter les capacités de travail d'un système, donc sa disponibilité.
Scalability
Par extension de ses capacités le système doit à tout moment faire face à la demande. Cette propriété s'applique aussi aux systèmes de stockage (disques durs, mémoire RAM) et aux communications.
Reliability
Fiabilité (systémique) est la capacité d'une personne ou d'un système pour exécuter et maintenir (entretenir) ses fonctions dans des circonstances ordinaires, aussi bien que des circonstances hostiles ou inattendues.
Manageability
C'est la capacité du système d’être géré comme une seule machine de manière simple. La gestion des ressources partagées, la modification de la configuration se fait sans déranger les utilisateurs et les processus en cours d’exécution.
Single-system image
Chaque membre du cluster (grappe de serveurs) est capable d’effectuer des opérations indépendamment. C’est le logiciel de « clusterisation » qui fournit une couche intermédiaire (middleware layer) qui connecte les ressources de chaque membre pour fournir un système unifié des ressources.
Tolérance aux pannes et puissance de calcul
La notion de disponibilité se base sur les concepts de résistance aux pannes - dans le but d'avoir des systèmes à haute disponibilité - ainsi que sur les concepts d'architectures parallèles - dans le but d'obtenir des systèmes à haute puissance de calcul capables d'exécuter de grandes quantités de traitements en même temps.
Classification de la disponibilité
La disponibilité d'un équipement ou d'un système est une mesure de performance qu'on obtient en divisant la durée durant laquelle ledit équipement ou système est opérationnel par la durée totale durant laquelle on aurait souhaité qu'il le soit. Ce ratio s'exprime classiquement en pourcents.
La classification des systèmes en terme de disponibilité conduit communément à 7 classes allant de non prise en compte (système disponible 90 % du temps et moins, donc indisponible plus d'un mois par an) à ultra disponible (disponible 99,99999 % du temps, donc indisponible de 0 à 3 secondes par an). Ces différentes classes correspondent au nombre de 9 (chiffre 9) dans le ratio de temps durant lequel les systèmes de la classe sont disponibles.
Type de gestion |
Indisponibilité / min. / an |
Disponibilité en % |
Classe de disponibilité |
Non géré |
50'000 (~ 35 j) |
90 |
1
|
Géré |
5'000 (~ 3.5 j) |
99 |
2 |
Bien géré |
500 (~ 8h) |
99.9 |
3 |
Tolérant les fautes |
50 |
99.99 |
4 |
Haute disponibilité |
5 |
99.999 |
5 |
Très haute disponibilité |
0.5 (30 s) |
99.9999 |
6 |
Ultra haute disponibilité |
0.05 (3 s) |
99.99999 |
7 |
N.B. : Une année dure 8'760 heures, soit 525'600 minutes.
Source: http://wapedia.mobi/fr/Tol%C3%A9rance_aux_pannes consulté le 24.07.2010
Le SPOF ou Single Point of Failure
Le SPOF est une approche cherchant à trouver dans un système informatique un endroit (généralement du matériel) qui en cas de défaillance ferait chuter tout le système. Un système sans SPOF est un système tolérant aux pannes, il continue ainsi de fonctionner si un élément vient à défaillir.
Le matériel comme élément sensible
Sur un serveur, un réseau, une unité de stockage plusieurs points sensibles en termes de protection des composants doivent faire l'objet d'une protection devant permettre à ceux-ci de supporter une défaillance d'un de leurs composants. La technique consiste à équiper les systèmes de composants "sensibles" redondants.
Alimentations électriques redondantes
Échangeables à chaud (sans interruption de service), certaines peuvent même se répartir la charge électrique.
T5 Onduleurs électriques |
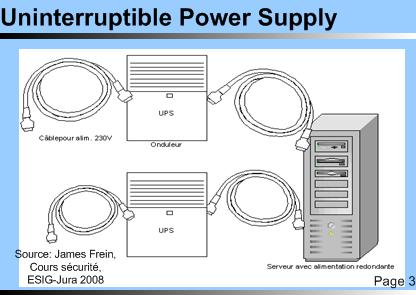 Uninterruptible Power Supply Uninterruptible Power Supply© TICSIPD 2010 |
| Prenant le relais en cas de coupure de l’alimentation principale. Pour une protection effective deux unité UPS (uninterruptible power supply) alimentées séparément et alimentant les serveurs séparément sont indiqués. Dans ce cas, chaque alimentation du serveur est liée à son propre onduleur, il n'y a plus de SPOF. |
Mémoire vive (RAM) à correction automatiqueECC)1
Les serveurs (mainframe5) peuvent être équipés de mémoire RAM redondante et échangeable à chaud.
Cartes réseau redondantes
Deux cartes réseau séparées mais vues par le système comme une seule carte. En cas de défaillance de l'une, l'autre prend le relai. Concernant les réseaux, on parle des techniques suivantes :
- Adapter Fault Tolerance(AFT)2
- Switch Fault Tolerance (SFT)
- Adaptive Load Balancing (ALB)
- FEC/Link Aggregation/802.3ad : static mode
- GEC/Link Aggregation/802.3ad : static mode.
Disques durs redondants RAID3 |
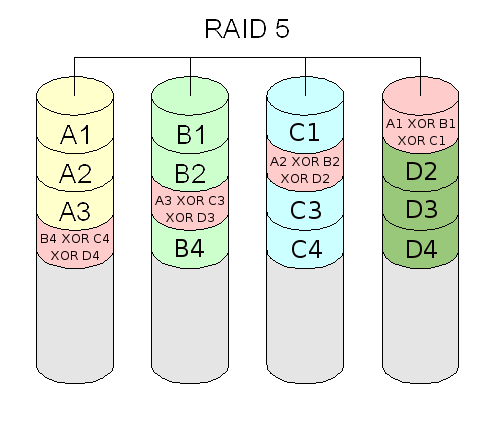 RAID 5 RAID 5
© Wikipédia
|
|
Échangeables à chaud. Divers types de RAID 1, 3, 5, 10 (0+1). Les interfaces IDE (Integrated Drive Electronics) disparaissent au profit des interfaces S-ATA4. |
Autres mesures de protection
⇒ Accès sécurisé aux ressources physiques du serveur, du réseau, aux unités de stockage.
⇒ Contrôle permanent des tensions d'alimentation, de la température du local des serveurs, des processeurs et du fonctionnement des ventilateurs / climatiseurs.
⇒ Filtres électriques pour éliminer les surtensions et parasites sur le réseau électrique.
⇒ Installation dans une chambre climatisée.
⇒ Installation dans un local avec détecteur d'incendie.
⇒ Installation dans un local avec système de gazage pour étouffer un incendie.
⇒ Local situé dans une partie du bâtiment non inondable.
Malgré toutes ces précautions et d'autres, une disponibilité de 100 % n’existe pas ! Celui qui tentera de vous en vendre une est un commercial.
Le logiciel comme point sensible
Lorsqu'on met en place un système avec une carte mère multiprocesseur, ces derniers sont gérés par un seul et même OS (Operating System système d'exploitation) créant un SPOF au niveau du logiciel. La défaillance de l'OS provoque la défaillance du système. Certains grands systèmes mainframes sont partitionnés, c'est-à-dire que le SMP physique est divisé en plusieurs systèmes SMP logiques ayant chacun son propre OS.
Les versions de Windows 2003 se déclinent de la manière suivante :
⇒ Windows 2003 Web : Load Balancing6 possible,
⇒ Windows 2003 Standard Server : Load Balancing possible,
⇒ Windows 2003 Enterprise : jusqu’à 8 nœuds en failover-clustering7, Load Balancing possibles
⇒ Windows 2003 Data Center : jusqu’à 8 noeuds en failover-clustering, Load Balancing possibles
⇒ Windows Server® 2008 R2 supporte beaucoup de fonctions clés de haute disponibilité permettant d'atteindre de hautes exigences de disponibilité : le failover-clustering le Network Load Balancing (NLB), la copie cache Shadow Copy, la sauvegarde Windows Serveur Backup et un nouvel environnement de rétablissement Windows Windows Recovery Environment.
Source Windows Server ® 2008 R2: http://www.microsoft.com/windowsserver2008/en/us/high-availability.aspx consulté le 25.07.2010.
Source : Pierre Jaquet août 2010.
Les clusters
<<Le logiciel de clustering est inclus dans certains systèmes d'exploitation — Windows Server version Entreprise est un exemple. Dans d'autres cas, il doit être installé en plus.
Certains logiciels de clustering ne peuvent réunir que des ordinateurs configurés d'une manière bien précise — c'est le cas de Windows. D'autres sont plus souples à l'emploi, notamment dans le monde Unix-Linux.
Le Stone SouperComputer en était l'archétype : il réunissait une bonne centaine de PC 486, de Pentiums de toutes marques et de serveurs DEC à processeurs Alpha, tous de vieilles machines abandonnées par leurs utilisateurs et offertes au Laboratoire national d'Oak Ridge, et ce matériel de brique et de broc fonctionnait très bien en cluster.
Physiquement, les ordinateurs du cluster sont connectés par un câblage dédié. Les serveurs en cluster ont donc deux cartes de réseau : une pour le réseau local normal et une pour le cluster.
Potentiellement, n'importe quel type de serveur peut être mis en cluster, mais on utilise le plus souvent des serveurs lames, leur haute densité étant particulièrement intéressante pour créer un système à la fois puissant et compact.
Un cluster présente les caractéristiques suivantes :
‒ les serveurs travaillent ensemble : chacun effectue une partie du travail;
‒ ils partagent une seule unité logique de disques;
‒ si l'un d'eux tombe en panne, les autres continuent son travail.
En fait, un cluster ressemble à un seul ordinateur qui serait doté de plusieurs processeurs et plusieurs mémoires centrales et dont le système d'exploitation gérerait la collaboration entre ces ressources.
Pour tirer le meilleur parti du clustering, il faut que les programmes d'application soient construits pour tourner sur plusieurs processeurs, que les compilateurs sachent gérer le multiprocessing et que le logiciel de clustering soit efficace.>>
Définition :
<<Un cluster est un groupe de serveurs qui forme un tout. Il a pour but d'améliorer les performances et la disponibilité du système. Un cluster peut rassembler aussi bien deux ordinateurs que des milliers de machines.>>
Pierre Jaquet, Les serveurs consulté le 06.08.2010
Il existe même des magazines en ligne dédiés au clustering sous Linux. Cluster Monkey est un exemple.
|
© TICSIPD 2010 |
<< En puissance de calcul, un cluster peut faire mieux qu'une mainframe à un prix dix ou vingt fois inférieur. Par contre, ses entrées-sorties sont généralement moins efficaces. Google exploite le plus grand cluster du monde (en réalité, c'est un ensemble de clusters) : il réunit plusieurs centaines de milliers de machines.Le cluster actuel le plus puissant est le Roadrunner d'IBM. Il se compose de serveurs lames et coûte 133 millions de dollars. Il est prévu pour atteindre 1,7 pétaflops, soit 1,7 million de milliards d'opérations en virgule flottante par seconde. Il occupe plus de 500 mètres carrés au sol. Une variété de traitement collaboratif plus lâche que le clustering proprement dit est le grid computing, comme dans le projet de recherche médicale Folding@home (http://folding.stanford.edu), auquel tout le monde peut participer. Sa puissance dépasse 3 pétaflops.>>Pierre Jaquet, Les serveurs, 2009 : consulté le 06.08.2010. |
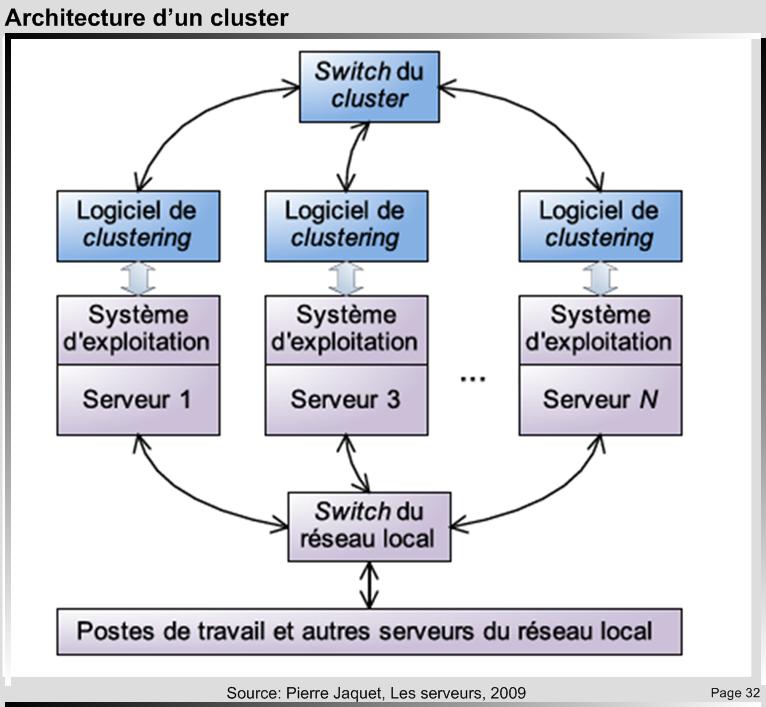
Le Clustering dédié à la tolérance aux pannes
Le principe du failover-clustering ou du High-availability cluster (HA cluster) dédié à la tolérance aux pannes consiste à mettre en place un logiciel de clustering qui regroupera plusieurs machines physiques (les nœuds) en une seule entité virtuelle (le cluster) vue de l’extérieur comme une seule machine. Le logiciel de clustering va s’occuper de maintenir dans un état cohérent l’ensemble des nœuds et détecter la défaillance d’un de ceux-ci et va s’occuper de le sortir du cluster. Lorsque le nœud défaillant est à nouveau opérationnel, il est détecté par le logiciel de clustering et réintègre le cluster.
Pratiquement, le serveur virtuel se voit attribuer une adresse IP que les machines de la grappe vont se partager. Toutes les machines composant la grappe ont une connexion virtuelle au serveur virtuel et peuvent répondre aux requêtes.
Système cluster distribué |
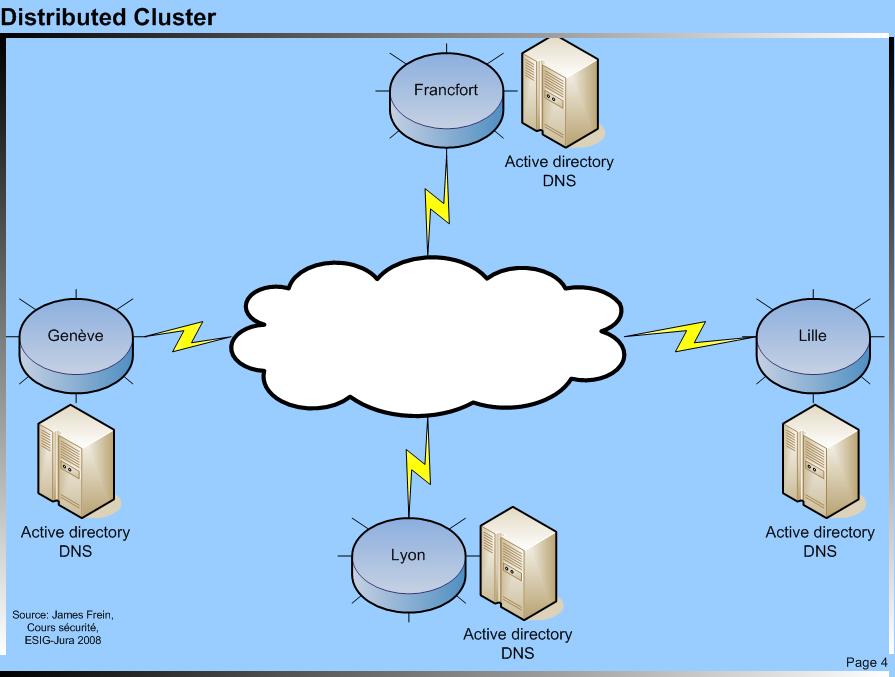 Distributed Cluster Distributed Cluster © TICSIPD 2010
|
| Un système cluster distribué est constitué de nœuds qui sont géographiquement (ou virtuellement) séparés et qui travaillent ensemble dans le but de fournir un même service. Dans le cas de la figure ci-dessous, il s’agit de fournir un annuaire et un service de traduction de nom de domaine commun aux quatre filiales se trouvant dans des villes différentes. Dans cette architecture, on fait tourner des services identiques sur des machines distantes afin que les utilisateurs locaux n’aient pas à transmettre leurs requêtes sur le WAN, qui par définition est plus lent que le LAN. |
Failover cluster |
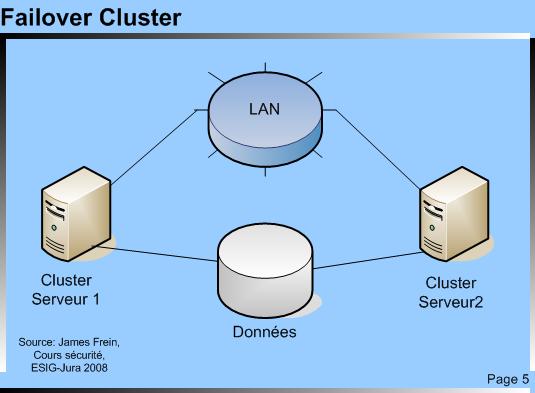 Failover Cluster Failover Cluster© TICSIPD 2010
|
| Ce type de cluster cherche à fournir un service de manière ininterrompue. Une unité de stockage (en général des disques SCSI (Small Computer System Interface) ou un système SAN (Storage Area Network)) accueille les données partagées, c’est-à-dire les données utilisées par l’application alors que l’application est installée en local sur chaque serveur. Un seul nœud travaille et a accès aux données partagées. Si celui-ci vient à tomber, le logiciel de clustering le détecte et passe la main au nœud de secours qui utilisera les données de la ressource partagée. |
Two-application distributed failover cluster
Dans ce type d’architecture, chaque nœud abrite une application qui est active, l’autre nœud hébergeant la même application qui est inactive. En cas de défaillance d’un nœud c’est l’autre qui va démarrer l’application passive pour maintenir le service. On peut s’attendre à une perte de performance du système si les machines ne sont pas dimensionnées pour être capable d’exécuter les deux applications simultanément sur une même machine. L’avantage de ce système est de tirer parti de la puissance des deux nœuds et de ne pas en laisser un dormir. Dans la littérature, on parle de clusters actifs/actifs ou à répartition de charge.
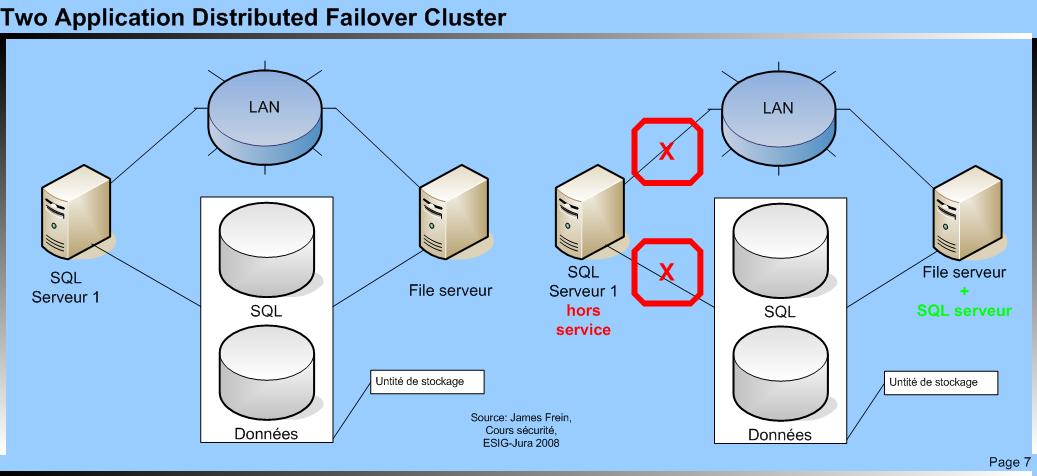 Two Application Distribueted Falover Cluster
Two Application Distribueted Falover Cluster
© TICSIPD 2010